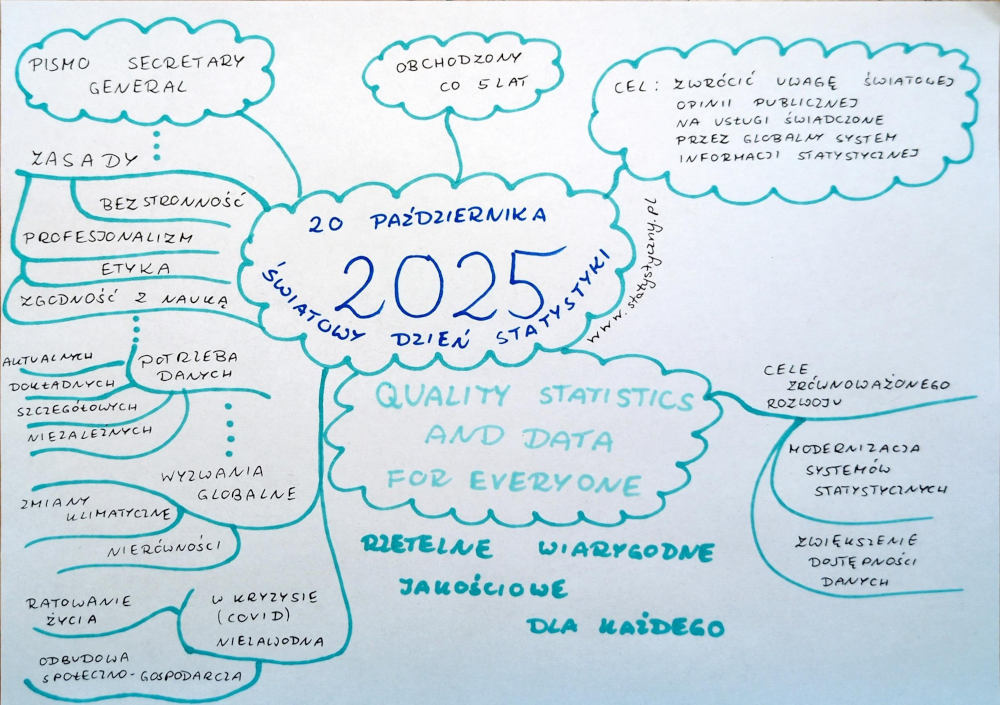
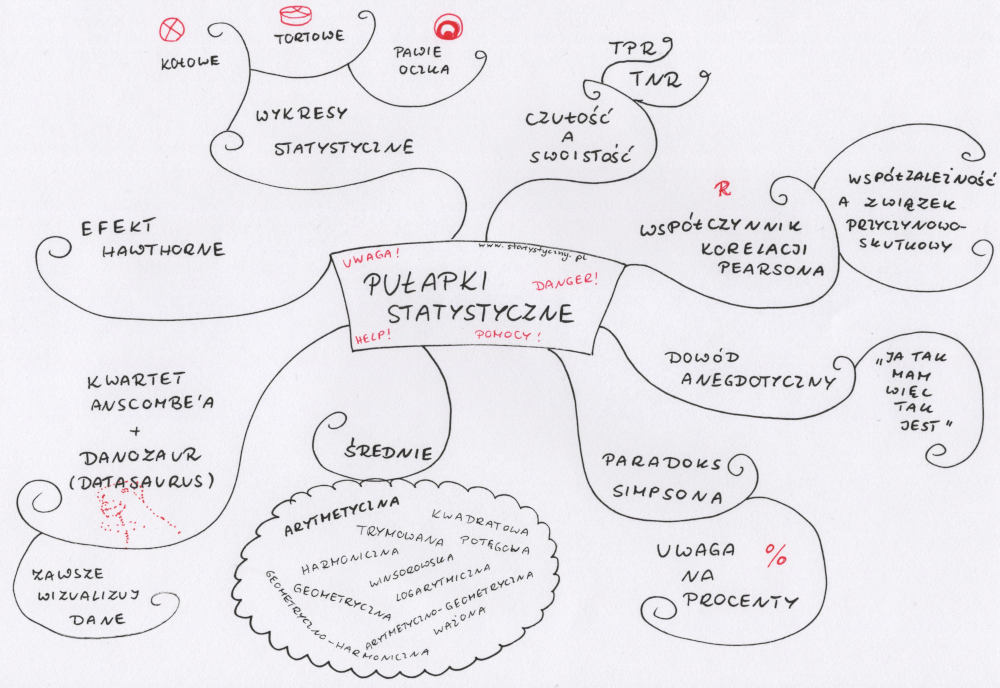
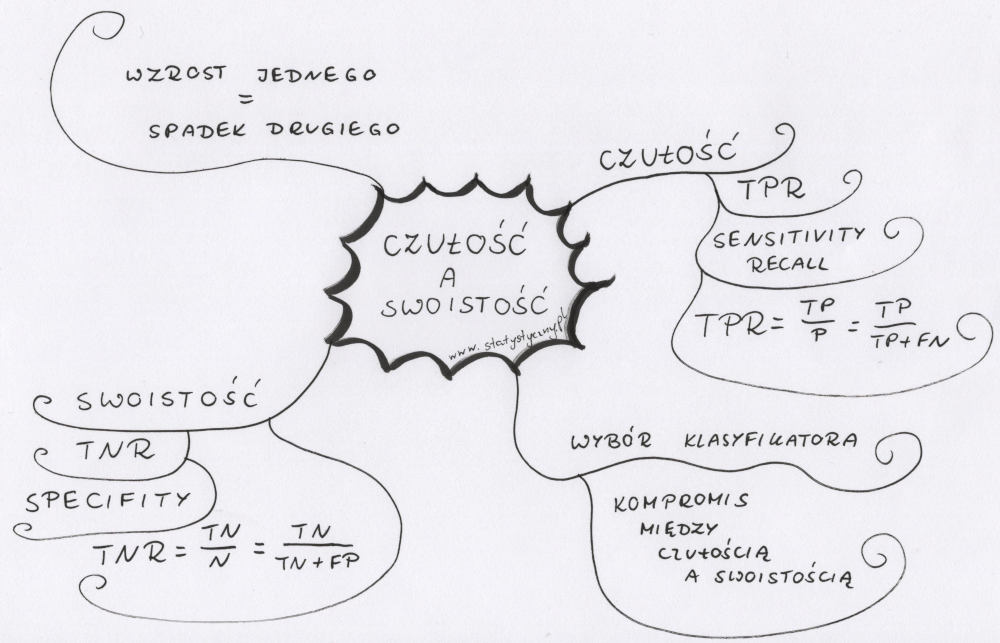
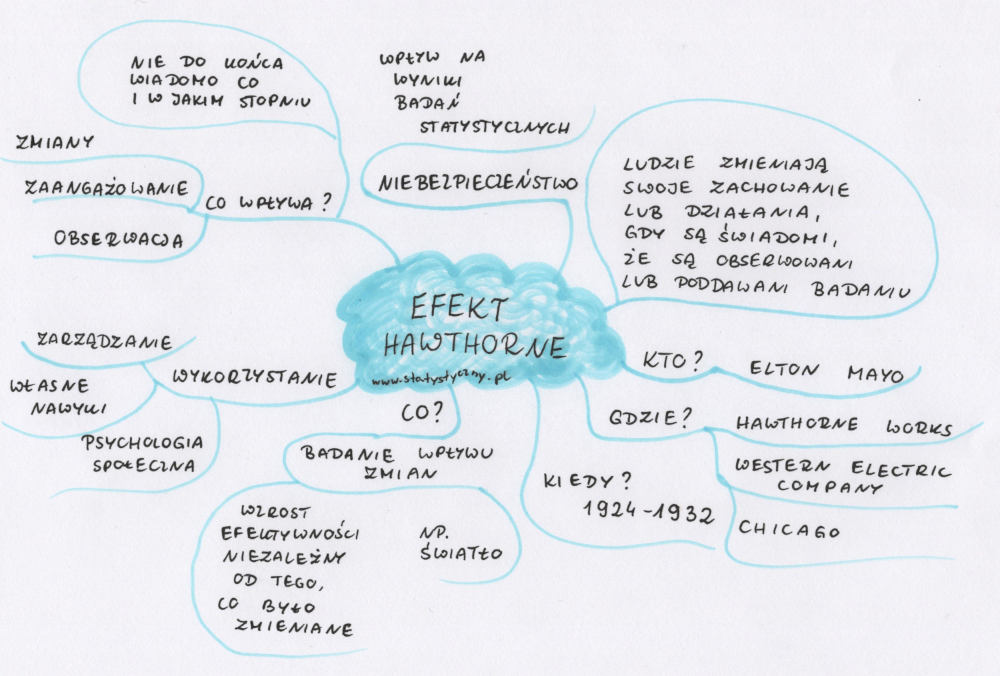
Indeks Jaccarda – to chyba kolejne pojęcie, które nie mówi zbyt dużo większości czytelników. Mnie zauroczył najbardziej jego początek – alpejskie łąki, kwiaty. Potrafię sobie wybrazić taki obrazek i tego „naukowca”, który zamiast zachwycać się pięknem przyrody, postanawia przeanalizować podobieństwo pomiędzy wspomnianymi łąkami. Jaki odsetek gatunków z jednej lokalizacji powtarza się na innej? Od tego się zaczęło, a potem było wykorzystywane do analizy zmian przebiegu koryta rzeki czy do porównań różnych tekstów. Aktualnie Indeks Jaccarda ma swoje zastosowanie w NLP więc warto jak najlepiej go poznać, żeby móc wykorzystać, kiedy pracujemy z danymi tekstowymi.
Indeks Jaccarda – od alpejskich kwiatków po analizę tekstu