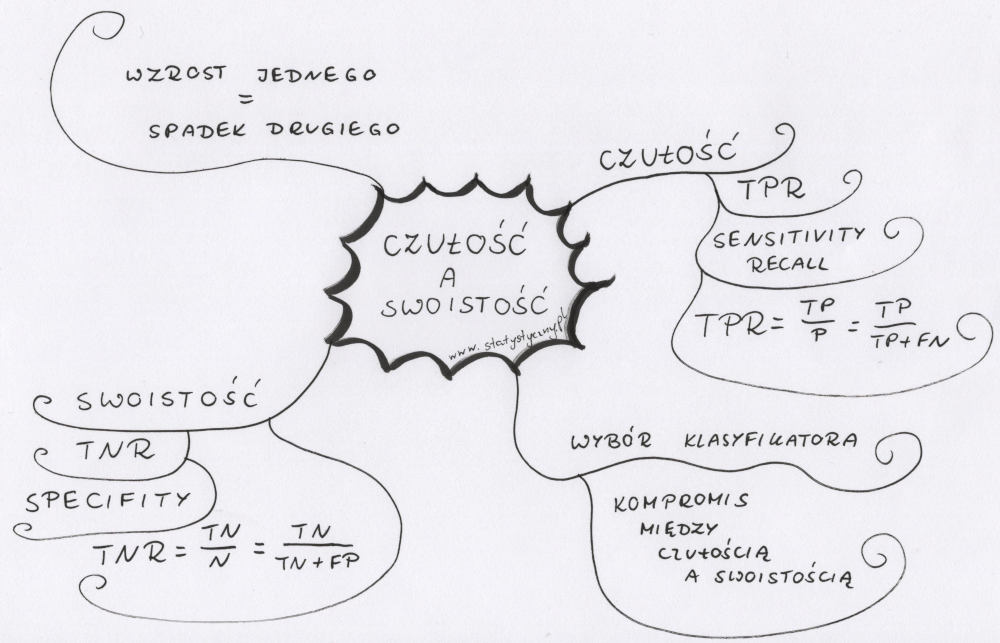
Po przerwie wracam do tematu macierzy błędów oraz do czułości (TPR, ang. sensitivity) i swoistości (TNR, ang. specifity). Dlaczego czułość i swoistość są tak ważne? Dlaczego wciąż o tym piszę począwszy od tematu macierzy błędów, przez ROC, AUC i współczynnik Youdena? Dlaczego powtarzam, że zwiększając jedno, wpływamy na drugie i że szukanie punktu odcięcia – kiedy uznamy kogoś za chorego (albo badany obiekt za jabłko) to bardzo poważna decyzja? Już Wam mówię, dlaczego.
Cytatów kilka – anglojęzyczne, ale warto przeczytać.
Czytam mądrą książkę na temat zdrowia, profilaktyki chorób i przeprowadzania różnych badań. I nie jest to żadna statystyczna książka, żaden podręcznik do statystyki, a i tak wpadam na temat czułości i swoistości. Mowa tu o „Outlive” napisanym przez Petera Attia. Poniżej kilka cytatów:
| Mainstream guidelines have been waving people away from some types of early screening, such as mammography in women and blood testing for PSA, prostate-specific antigen, in men. In part this has to do with cost, and in part this has to do with the risk of false positives that may lead to unnecessary or even dangerous treatment. |
| With all diagnostic tests, there is a trade-off between sensitivity, or the ability of the test to detect an existing condition (i.e., its true positive rate, expressed as a percentage), and specifity, which is the ability to determine that someone does not have that condition (i.e., true negative rate). Together, these represent the test’s overall accuracy. In addition, however, we have to consider the prevalence of the disease in our target population. How likely is it that the person we are testing actually has this condition? |
| Mammography has a sensitivity in the mideighties and a specifity in the low nineties. But if we are examining a relatively low-risk population, perhaps 1 percent of whom actually have breast cancer, then even a test with decent sensitivity is going to generate a fairy large number of false positives. In fact, in this low-risk group, the „positive predictive value” of mammography is only about 10 percent – meaning that if you do test positive, there is only about a one-in-ten chance that you actually have breast cancer. |
Skracając dla tych, którym z angielskim nie po drodze, Peter Attia uświadamia czytelników, że zdarzają się sytuacje, kiedy badania typu mammografia albo PSA nie są zalecane dla wszystkich. Powodem tego jest zbyt duże ryzyko fałszywie pozytywnych wyników, które są związane z wysokimi kosztami, a następnie niepotrzebnym i niebezpiecznym leczeniem zdrowych osób.
Każdy test diagnostyczny zmaga się z problemem kompromisu pomiędzy czułością a swoistością. W każdym teście badamy jego możliwości rozróżnienia pomiędzy osobami naprawdę zdrowymi (TP – true positive) i naprawdę chorymi (TN – true negative), a tymi fałszywie rozpoznanymi jako zdrowe i chore (FP – false positive i FN – false negative).
Jeśli czułość i swoistość jakiegoś testu są w okolicy 80-90%, a ogólnie społeczeństwo jest raczej zdrowe, to jest duże prawdopodobieństwo, że osoba, która uzyskała pozytywny wynik jest absolutnie zdrowa.
Czułość – co to jest?
czułość (ang. recall, sensivity, true positive rate)
\(TPR=\frac{TP}{P}=\frac{TP}{TP+FN}\)
Czułość mówi nam o tym, jaki jest udział prawidłowo zaprognozowanych przypadków pozytywnych (TP) wśród wszystkich przypadków pozytywnych (również tych, które błędnie zostały zaklasyfikowane do negatywnych – FN).
Warto pamiętać, że jeśli algorytm nie zaklasyfikuje żadnego pozytywnego przypadku błędnie (czyli nic nie trafi do kategorii FN), to czułość będzie wynosić 1. Nawet jeśli będzie błędnie klasyfikował FP, czyli negatywne przypadki będą trafiać do kategorii pozytywnej. We wzorze na czułość nie pojawiają się w ogóle wartości FP i TN.
Czułość jest parametrem, który powinien przyjmować jak największą wartość (czyli dążyć do jedynki).
Swoistość – co to jest?
Swoistość, odsetek prawidziwie negatywnych (ang. specifity, true negative rate)
\(TNR=\frac{TN}{N}=\frac{TN}{TN+FP}\)
Swoistość jest tym dla klasy „negatywnej”, czym czułość dla klasy „pozytywnej”. Mierzymy, jak dużo ze wszystkich negatywnych przypadków zostało rzeczywiście zaklasyfikowanych do tej kategorii.
Duża swoistość pokazuje, że klasyfikator rzadko się myli, jeśli chodzi o negatywne przypadki. Tak więc jeśli pokaże, że coś jest pozytywne, to możemy z dużym prawdopodobieństwem się spodziewać, że takie rzeczywiście jest.
We wzorze na swoistość nie pojawiają się wartości TP i FN. Wystarczy, że nie będzie przypadków fałszywie pozytywnych, a wartość swoistości będzie równa 1.
Dlaczego zwiększając czułość zmniejszamy swoistość?
Żeby o tym opowiedzieć, to przypomnę nasze analizy jabłek i pomidorów – temat, który pojawił się już w kilku wcześniejszych wpisach. Nasz algorytm od lewej strony ustawił jabłka i pomidory w takiej kolejności, że pierwszy owoc ma największe prawdopodobieństwa bycia jabłkiem, a ostatni najmniejsze. Jak widać, jego działanie nie jest najlepsze i już na drugim miejscu pojawił się pomidor (algorytm twierdzi, że jego bycie jabłkiem jest bardziej prawdopodobne niż następnego jabłka).
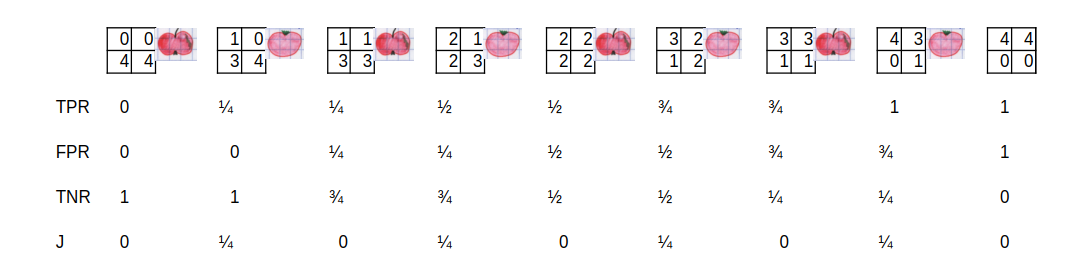
W tym momencie spójrzmy na to, co interesuje nas na tym obrazku. Przesuwając punkt podziału na jabłka i pomidory wpływamy na czułość i swoistość. W pierwszym wierszu mamy obliczenia dla czułości (TPR), a w trzecim dla swoistości (TNR). Jeśli wszystko uznamy za pomidory, to TPR wynosi 0, ale za to TNR wynosi dokładnie 1. Wraz z przesuwaniem miejsca podziału na jabłka/pomidory możemy zauważyć wzrost TPR (korzystny) i spadek TNR (niekorzystny). Im bardziej nam zależy na tym, żeby nie mieć błędnie zaklasyfikowanych jabłek, tym bardziej ryzykujemy, że pojawią się błędnie zaklasyfikowane pomidory. I póki nie mamy idealnego algorytmu, który potrafi uszeregować najpierw tylko jabłka, a następnie tylko pomidory, tak długo musimy się liczyć z tym, że szukamy najlepszego kompromisu między czułością a swoistością.
Jakie możemy wyciągnąć z tego wnioski?
Kiedy zajmujemy się jakąkolwiek klasyfikacją, to czasem wynik jest ewidentny, a czasem algorytm ma wątpliwości. Wyobraźmy sobie klasyfikację produktów spożywczych. Jeśli mamy podział na sery i wędliny, to raczej „żółty ser” trafi do serów, a „pieczona szynka” do wędlin. A co jeśli mamy „topiony ser z szynką”? Będzie sobie gdzieś na granicy. I jeden algorytm skupi się bardziej na słowie „ser”, a inny na słowie „szynka”.
Jeśli robimy w medycynie testy diagnostyczne, to też mamy ludzi ewidentnie chorych i ewidentnie zdrowych. Ale jest też cała grupa ludzi, którzy mają wyniki gdzieś pomiędzy. Tych ludzi, których różne algorytmy są gotowe zaklasyfikować do różnych grup. Tych ludzi, których wynik bardzo zależy od wybranego punktu, w którym decydujemy się ustawić granicę pomiędzy pozytywnym i negatywnym wynikiem testu.
Dla nas – odbiorców takich testów – ważna jest informacja, że wynik testu nigdy nie jest w 100% pewny. Oczywiście, twórcy testów robią wszystko, żeby działały one jak najlepiej. Żeby wynik odzwierciedlał rzeczywistość. Ale nie zawsze jest to możliwe. W większości przypadków wynik będzie prawidłowy – bo taki jest cel testów i badań. Ale zawsze istnieje jakiś ułamek możliwości, że trafiliśmy to tego małego koszyczka z fałszywie pozytywnymi lub fałszywie negatywnymi wynikami.
Nie chciałabym, żeby to zabrzmiało, jakbym sugerowała, że wyniki badań i testów należy podważać. Zdecydowanie nie. Wszyscy robią tak, żeby prawdopodobieństwo błędu było minimalne. Prawie zawsze wynik będzie prawidłowy. Ja tylko chcę uczulić, że istnieje jakaś mała szansa, że jednak nie.
Powyższy artykuł jest bardzo mocno powiązany z licznymi poprzednimi artykułami:
- Macierz błędów i co z tego wynika
- ROC – Receiver Operating Characteristic
- AUC – Area under curve – czyli co kryje się pod krzywą?
- Współczynnik Youdena, jak połączyć czułość i swoistość i znaleźć punkt odcięcia
Na jego pomysł wpadłam podczas lektury książki „Outlive” i myślę, że dobrze uzupełnia to, o czym pisałam wcześniej. Mam nadzieję, że Wam przypadł do gustu i że rzeczywiście pomaga zrozumieć, dlaczego ważny jest nie tylko dobry klasyfikator, ale również odpowiedni dobór punktu odcięcia, a także świadomość, że wynik każdego testu diagnostycznego nie zawsze jest zgodny z rzeczywistością.
Jeśli uważacie, że to co piszę jest wartościowe, to od niedawna możecie się zrzucić na symboliczną „kawkę”. To dodaje skrzydeł i motywuje do dalszego pisania.

Ja natomiast zapraszam Was na facebooka, sugeruję skorzystanie ze spisu treści i wybranie sobie czegoś ciekawego do przeczytania. Jakie są Wasze ulubione artykuły? Czy tekst o czułości i swoistości do nich dołączy?
Pozdrawiam ciepło i serdecznie!
Krystyna Piątkowska