Machine Learning, o którym napisałam ostatnio to temat rzeka. Ale ponieważ pierwszy krok w tej rzece już uczyniłam, to pora na kolejny. Dzisiaj postanowiłam rzucić się na głęboką wodę i opisać nie tylko klasyfikację metodami uczenia maszynowego, ale pójść dalej i opowiedzieć, jak algorytmy radzą sobie z tak trudnym tematem jak klasyfikacja tekstu.
Dlaczego klasyfikacja tekstu to wyzwanie? Dlatego, że komputery nie rozpoznają słów i żeby analizować i porównywać to, co my piszemy, musimy tak przekształcić tekst, żeby był zrozumiały dla algorytmów.
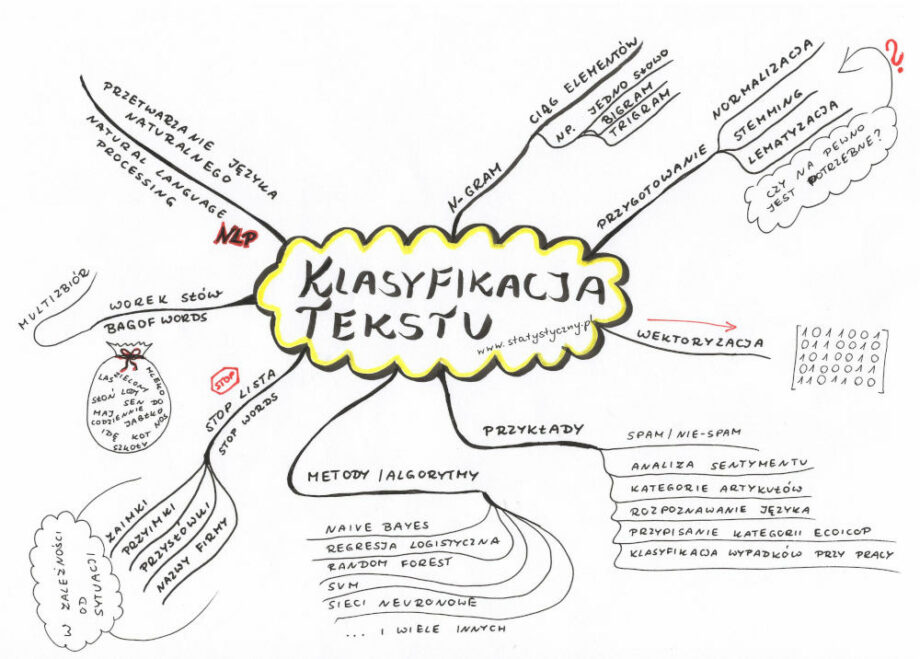
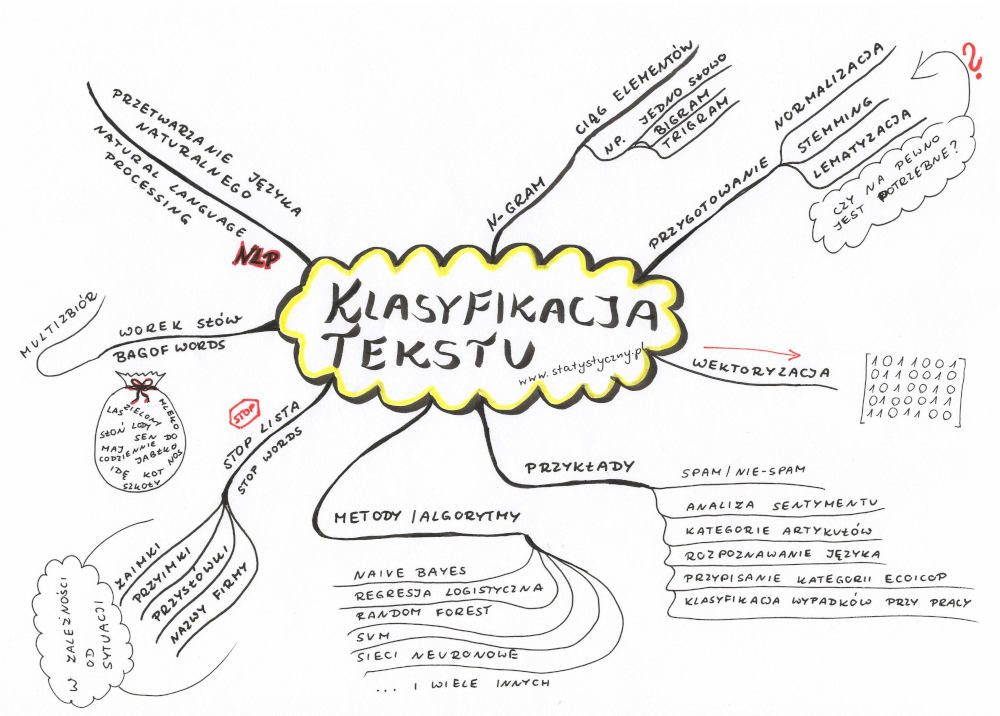
Przetwarzanie języka naturalnego
Przetwarzanie języka naturalnego (ang. NLP – Natural language processing) to właśnie temat, z którym należy zapoznać się, kiedy przed nami staje wyzwanie pod tytułem klasyfikacja tekstu. Ale jest to temat dużo szerszy więc nie będę za dużo o tym przetwarzaniu opowiadać, ale skupię się na tych jego aspektach, które wydają mi się najbardziej istotne dla klasyfikacji. Reszta być może kiedyś indziej, jeśli okaże się przydatna.
„Bag of words” czyli tak zwany „worek słów”
Mamy zdanie. Jakiekolwiek. I żeby algorytm mógł z nim cokolwiek zrobić, to musi to zdanie zostać podzielone na jakieś mniejsze kawałki. Jednym z podejść w klasyfikacji tekstu jest właśnie stworzenie „worka słów”. Każde słowo użyte w tym zdaniu zostaje wyodrębnione i wrzucone do multizbioru. Tak więc jeśli mamy dwa zdania: „Ala ma kota.” i „Idę do szkoły.”, to w worku słów znajdzie się sześć słów: Ala, ma, kota, Idę, do, szkoły. Ich kolejność nie będzie miała znaczenia.
n_gram
Zwykle do worka słów wrzucamy pojedyczne słowa, ale czasem warto skorzystać z n-gramów. N-gram to ciąg elementów z danej próbki tekstu lub mowy. Zazwyczaj jednym elementem jest pojedyncze słowo (ale w określonych przypadkach mogą też być to fonemy, litery lub sylaby). W przypadku powyższych zdań, gdybyśmy szukali bigramów (2-gramów), to byśmy otrzymali: Ala ma, ma kota, Idę do, do szkoły. Kolejnym stopniem n-gram są trigramy (Ala ma kota, Idę do szkoły), a potem 4-gramy itd. Wybór czy chcemy korzystać tylko z analizy pojedycznych słów, czy n-gramów, to jeden z etapów doboru jak najlepszego modelu do klasyfikacji.
Wektoryzacja
Z workiem słów blisko związany jest termin wektoryzacji.
Kiedy używamy najprostszego wektoryzatora (CountVectorizer), to zlicza on liczbę wystąpień każdego wyrazu (lub n_gramu) w tekście i przedstawia za pomocą wektora składającego się z liczb naturalnych. Każda liczba informuje, ile razy dany element wystąpił w analizowanym tekście.
Taki wektor jest dużo łatwiejszy do analizy przez algorytmy komputerowe niż wyrazy, zdania, artykuły.

Stop lista (stop words)
Stop lista (po angielsku zwana „stop words”) to lista słów, które właściwie nie mają znaczenia dla algorytmu. Najczęściej są to spójniki, przyimki, zaimki – słowa, które nie niosą za sobą zbyt dużo treści. I jeśli chcemy zaklasyfikować tekst, to trzeba zdecydować, czy chcemy wykorzystać wszystkie słowa, czy wolimy wyeliminować te, które niewiele wnoszą i w ten sposób zmniejszyć liczbę słów w naszym multizbiorze.
Przykład: Idę do sklepu spożywczego po pomidory i jabłka.
Z powyższego zdania bez utraty znaczenia możemy spróbować pozbyć się słów „do”, „po” oraz „i”. Chociaż gdyby jednak celem naszych działań było rozpoznawanie języka, z którego dane zdanie pochodzi, to warto pozostawić nawet słowa najczęściej używane, bo to one mogą wpływać na rozróżnienie. Stąd też właśnie potrzeba za każdym razem przemyśleć, czy warto ze stop listy korzystać czy nie.
Często są z góry przygotowane stop listy dla różnych języków. To bardzo ułatwia pracę. Warto jednak zawsze sprawdzić, czy przydadzą się w naszej klasyfikacji albo czy chcemy taką stop listę w jakiś sposób rozszerzyć o własne słowa.
Normalizacja, stemming, lematyzacja
Normalizacja
Czym jest normalizacja? Polega na takim przetworzeniu tekstu, żeby miał spójną formę, która ułatwi dalszą interpretację tego tekstu. W zależności od potrzeb, różnie może wyglądać taka normalizacja.
Poniżej kilka różnych przykładów, jak może wyglądać normalizacja :
- zmiana wielkości liter na małe lub wielkie – dzięki czemu przy analizie tekstu nie ma znaczenia, czy dany wyraz stał na początku zdania (i był napisany z wielkiej litery), czy gdzieś w środku. Ma to też swoje minusy – ptak karolinka zostanie zrównany z dziewczynką Karolinką, a śląski Browarek (powiat zawierciański, gmina Kroczyce) nie będzie się niczym różnił od browarka wypitego w piątek po pracy.
- rozwinięcie skrótów – która powoduje, że zamiast „p.o.” będziemy mieć „pełniącego obowiązki”, a „m.in” zostanie zastąpione „między innymi”. Tu jednak też czają się pułapki. Skąd mamy wiedzieć, czy „r.” oznacza rok czy rodzaj? To co może nam pomóc, to kontekst, który pozwala domyślić się, o które znaczenie skrótu chodzi.
- normalizacja skrótowców – czym są skróty to zwykle wiemy, a co nazywamy skrótowcami? AE – Akademia Ekonomiczna, PAN – Polska Akademia Nauk, ZUS – Zakład Ubezpieczeń Społecznych, GUS – Główny Urząd Statystyczny, AGD – artykuły gospodarstwa domowego. Takie skrótowce mogą występować jako odrębny wyraz, albo można zdecydować, że chcemy je rozdzielić na wyrazy składowe. I czasem wolimy jeden skrótowiec (AGD w jednym słowie łatwiej się interpretuje), a czasem warto rozdzielić, bo chocażby skrótowiec US może oznaczać zarówno Urząd Skarbowy, Urząd Statystyczny jak i Uniwersytet Śląski.
- konwersja wyrażeń numerycznych i wyrażeń słowno-numerycznych do postaci słownej
- normalizacja znaków specjalnych – takich jak symbol akapitu czy znak zastrzeżenia prawa autorskiego
- usunięcie lub zmiana znaków interpunkcyjnych – można usuwać wszelkie kropki, przecinki i znaki zapytania. Czasem należy zamienić np. myślnik w wyrażeniu 12-15 na „od 12 do 15”
- usuwanie (lub zmienianie) znaków diakrytycznych – a znaki diakrytyczne to wszelkie akcenty czy haczyki pojawiające się przy różnych literach. W polskim alfabecie spotykamy dziewięć liter tworzonych przez znaki diakrytyczne: ą, ć, ę, ł, ń, ó, ś, ź oraz ż. W innych językach mamy litery akcentowane: é, á, ó. Są też tyldy jak w hiszpańskim słowie sueño albo umlauty jak w niemieckim nazwiku Müller. I wiele innych znaków, w zależności od języka.
- usunięcie lub przekształcenie wybranych lub wszystkich znaków typograficznych – znaki typograficzne to apostrofy, ukośniki, at (zwane potocznie małpką), plusy, procenty, nawiasy itp. Czasem warto je usunąć (na przykład cudzysłów, nawias), czasem wykorzystać ich nazwę (2+3=5 można zapisać jako dwa plus trzy równa się pięć).
- usunięcie elementów niezwiązanych z tekstem (np. tabele, rysunki)
Stemming
Stemming jest to proces usunięcia ze słowa końcówki fleksyjnej, w efekcie którego pozostaje tylko temat wyrazu. Najlepiej zrozumieć to na przykładzie. Proponuję zbiór wyrazów: truskawkowy, truskawce, truskawkami, truskawkowo, truskawkę, truskaweczka. Częścią wspólną tych wyrazów jest część „truskaw” i to może być potraktowane jako temat wyrazu. Końcówki fleksyjne: -kowy, -ce, -kami, -kowo, -eczka informują o zmianie części mowy, przypadku, liczby lub o zdrobnieniu wyrazu.
Lematyzacja
Lematyzacja to sprowadzenie słowa do jego podstawowej postaci. Na przykład w przypadku czasownika to najczęściej będzie bezokolicznik, w przypadku rzeczownika sprowadzamy do mianownika liczby pojedynczej.
Czy trzeba?
Czy powyższe zabiegi zawsze są konieczne? Moja odpowiedź brzmi, że zdecydowanie nie. Jeśli chcemy rozróżniać różne towary w sklepie, to jeśli drożdżówkę z jabłkiem, jabłecznik, dżem jabłkowy i jabłko będziemy skracać do „jabłk” to utrudni nam to prawidłowe rozpoznanie kategorii zamiast je ułatwić. Jeśli chcemy rozróżniać mleko tłuste i chude, to informacje 0.5% oraz 3.2% są dla nas istotne, a wręcz kluczowe do rozpoznania prawidłowej kategorii. Ale już analizując teksty z internetu warto ujednolicić małe i wielkie litery oraz pozbyć się znaków diakrytycznych, których wielu użytkowników nie stosuje w swoich wypowiedziach. Tak więc uważam, że na samym początku analizy bardzo ważne jest szczegółowe przemyślenie tematu i określenie, z których elementów normalizacji, stemmingu i lematyzacji chcemy korzystać. Przy czym często w różnych językach różne opcje różnie się sprawdzają.
Klasyfikacja tekstu
I jak już mamy przygotowane odpowiedno nasze teksty, to dopiero teraz przechodzimy do sedna tematu, który brzmi klasyfikacja tekstu. Przypomnę z poprzedniego artykułu:
Algorytmy klasyfikacyjne – to takie algorytmy, które pozwalają przypisać dane do odpowiednich kategorii. Przykład najbardziej znany, to podział maili na spam i nie-spam. Oprócz tego rozpoznawanie kwiatków po wyglądzie albo ręcznie napisanych cyferek. Jeśli przypisujemy dane do dwóch kategorii, to mamy do czynienia z klasyfikacją dwuklasową (ang. two-class classification). Jeśli etykiet jest więcej, to mówimy o klasyfikacji wieloklasowej (ang. multiclass classification).
W przypadku klasyfikacji tekstu chcemy przypisać kategorie dla każdego analizowanego tekstu. Może to być zdanie, zbitek słów albo nawet dłuższy mail albo artykuł. Wszystko w zależności od potrzeb.
Klasyfikacja tekstu – przykłady
Ale co możemy w ogóle klasyfikować? Poniżej kilka przykładów. I pamiętajmy, że zupełnie nie wyczerpują one pełnej listy możliwości. Każdy tekst można spróbować klasyfikować. Każdy zbiór tekstów daje nam przeróżne możliwości. A algorytmy machine learning mogą być wspaniałym źródłem, żeby z tych możliwości korzystać.
- Maile podział na spam i na nie-spam – każdy z nas cieszy się, kiedy klient poczty posortuje nam maile na te, które wyczekujemy z niecierpliwością oraz te, które są tylko śmieciami, reklamami. To nie magia pozwala na rozróżnienie, ale właśnie odpowiednie algorytmy wykorzystujące machine learning.
- Analiza sentymentów – to taki proces, który pozwala na rozpoznanie, czy tekst jest napisany w tonie pozytywnym, negatywnym czy neutralnym.
- Kategorie artykułów – często artykuły mają przypisane kody „polityka”, „geografia”, „świat”, „kuchnia”, „ogród” itp. To też można ogarnąć za pomocą metod machine learning.
- Rozpoznawanie języka – algorytmy machine learning pozwalają rozpoznać, w jakim języku był napisany dany tekst.
- Przypisanie kategorii ECOICOP do towarów – czy chleb to pieczywo czy pozostałe wyroby piekarnicze? A jak zaklasyfikować nutellę albo dwa kilogramy jabłek? Jeśli trzeba zaklasyfikować coś do odpowiedniej kategorii, również można odpowiednio nauczyć algorytmy machine learning.
- Wypadki przy pracy – na podstawie opisu sporządzonego w zakładzie pracy, można wypadek dopasować do odpowieniej kategorii, która jest potrzebna do analiz przygotowywanych przez urzędy.
Klasyfikacja tekstu – przykładowe algorytmy
- Naive Bayes
- Random Forest
- SVM
- Logistic Regression
- sieci neuronowe
Powyższe algorytmy to tylko kilka przykładów – jest ich dużo więcej. Wypisałam akurat te, ponieważ z nich korzystałam w moim ostatnim projekcie zawodowym. Ale warto szukać, doczytywać, analizować, co najbardziej przyda się w przypadku jakiegoś konkretnego wybranego przez nas przykładu klasyfikacji tekstów.
Jeśli ktoś korzysta z Pythona, to do analiz machine learning polecam bibliotekę scikit learn.
Droga Czytelniczko! Drogi Czytelniku!
Dziękuję, że przeczytałaś/przeczytałeś mój artykuł. Mam nadzieję, że spełnił Twoje oczekiwania. Jeśli chcesz się podzielić swoimi przemyśleniami, to napisz do mnie na adres [email protected] albo znajdź mnie na Facebooku.
Zapraszam Cię również do zapoznania się ze spisem treści (staram się go aktualizować, choć nie zawsze to wychodzi) – jeśli lubisz statystykę, to na pewno znajdziesz coś do poczytania.
A jeśli w ramach podziękowania za ten wpis zechcesz zaprosić mnie na przysłowiową “wirtualną kawę”, to będę niezwykle zobowiązana. Co prawda kawy raczej nie pijam, ale kubek dobrej herbaty – z prawdziwą przyjemnością. A ponieważ w każdy artykuł wsadzam mnóstwo serducha i swojego wysiłku, to tym bardziej poczuję się doceniona.

Pozdrawiam Cię serdecznie i życzę miłego dnia!
Krystyna Piątkowska